HERBench: A Benchmark for Multi-Evidence Integration in Video Question Answering
VideoQA benchmark where every question requires ≥3 dispersed evidence segments
Abstract
Video Large Language Models (Video-LLMs) are rapidly improving, yet current Video Question Answering (VideoQA) benchmarks often allow questions to be answered from a single salient cue, under-testing reasoning that must aggregate multiple, temporally separated visual evidence. In this direction, we present HERBench, a VideoQA benchmark purpose-built to assess multi-evidence integration across time. Each question is constructed to require aggregating at least three non-overlapping evidential cues across distinct video segments (so neither language priors nor a single snapshot can suffice). HERBench comprises 26K five-way multiple-choice questions organized into twelve compositional tasks that probe identity binding, cross-entity relations, temporal ordering, co-occurrence verification, and counting. To make evidential demand measurable, we introduce the Minimum Required Frame-Set (MRFS)-the smallest number of frames a model must fuse to answer correctly-and show that HERBench imposes substantially higher demand than prior datasets (mean MRFS 5.5 vs. 2.6-4.2). Evaluating 13 state-of-the-art Video-LLMs on HERBench reveals pervasive failures: accuracies of 31-42% are only slightly above the 20% random-guess baseline. We disentangle this failure into two critical bottlenecks: (1) a retrieval deficit, where frame selectors overlook key evidence, and (2) a fusion deficit, where models fail to integrate information even when all necessary evidence is provided. By making cross-time evidence both unavoidable and quantifiable, HERBench establishes a principled target for advancing robust, compositional video understanding.
Benchmark Overview

HERBench enforces high evidential requirements by design: questions draw on dispersed cues across long-form videos, and answers are balanced to prevent positional bias. The MRFS (Minimum Required Frame Set) metric reports the smallest number of frames a model with a fixed selector must fuse to answer correctly, separating genuine multi-frame reasoning from single-cue shortcuts.
Leaderboard
Top-1 accuracy (%) with a 16-frame uniform budget.
| Rank | Model | Selector | Frames | Overall | TR&C | R&T | GC&V | ME&N |
|---|---|---|---|---|---|---|---|---|
| 1 | Ovis-2.5-9B | Uniform | 16 | 42.1 | 18.9 | 73.5 | 46.8 | 29.2 |
| 2 | InternVL3.5-14B | Uniform | 16 | 41.5 | 37.7 | 69.3 | 31.1 | 27.8 |
| 3 | InternVL3.5-8B | Uniform | 16 | 41.1 | 33.6 | 70.2 | 29.7 | 30.8 |
| 4 | Gemini-2.5-Flash | Uniform | 16 | 40.3 | 29.7 | 69.9 | 34.9 | 26.8 |
| 5 | MiniCPM-V4.5-8B | Uniform | 16 | 39.9 | 23.8 | 71.1 | 39.7 | 24.9 |
| 6 | Qwen2.5-VL-72B | Uniform | 16 | 39.7 | 26.9 | 70.9 | 36.6 | 24.4 |
| 7 | GPT-4.1 | Uniform | 16 | 39.4 | 25.4 | 66.0 | 37.1 | 29.0 |
| 8 | Qwen3-VL-8B | Uniform | 16 | 38.3 | 19.0 | 68.7 | 40.6 | 25.2 |
| 9 | LLaVA-OneVision1.5-8B | Uniform | 16 | 38.1 | 26.1 | 67.7 | 33.6 | 24.9 |
| 10 | Qwen2.5-VL-7B | Uniform | 16 | 35.9 | 21.8 | 60.6 | 38.7 | 22.6 |
| 11 | LLaVA-OneVision-7B | Uniform | 16 | 35.6 | 27.3 | 59.1 | 30.1 | 26.0 |
| 12 | Gemma-3-27B | Uniform | 16 | 33.8 | 32.0 | 58.4 | 21.5 | 23.5 |
| 13 | LLaMA-4-Scout-17B | Uniform | 16 | 31.4 | 18.8 | 57.3 | 25.5 | 24.2 |
| Random baseline (5-way MCQ): 20% | ||||||||
Observed bottlenecks
Evidence retrieval: learned frame selectors beat uniform sampling yet trail oracle evidence
frames.
Evidence fusion: even with oracle frames, models often over-weight a single frame rather than
integrating dispersed cues, missing the right answer.
Task Families
12 compositional tasks grouped into 4 reasoning families:
1. Temporal Reasoning & Chronology (TR&C)
2. Referring & Tracking (R&T)
3. Global Consistency & Verification (GC&V)
4. Multi-Entity Aggregation & Numeracy (MEA&N).
Arrange four shot descriptions into the correct chronological order using content cues alone.
Evidential Requirement (MRFS)
We quantify how much visual evidence a VideoQA item requires using the Minimum Required Frame-Set (MRFS): the smallest number of frames that must be integrated for a model to answer correctly. Higher MRFS indicates that questions are not solvable from a single salient snapshot and instead require integrating temporally separated cues.
Cross-benchmark comparison. HERBench exhibits the highest evidential requirement (mean MRFS = 5.49), exceeding LongVideoBench (4.07), MVBench (3.52), and NExT-QA (2.61). Notably, this higher MRFS is achieved despite a shorter average video duration than LongVideoBench, suggesting the difficulty is driven by evidential density rather than video length alone. This metric-level effect is consistent with the benchmark construction, which explicitly filters out items that are solvable with too few frames.
Protocol. Because MRFS is defined with respect to a model f, a question-conditioned frame selector r, and a frame budget x, we report values under a standardized setup to enable apples-to-apples comparison across benchmarks.
Benchmark statistics
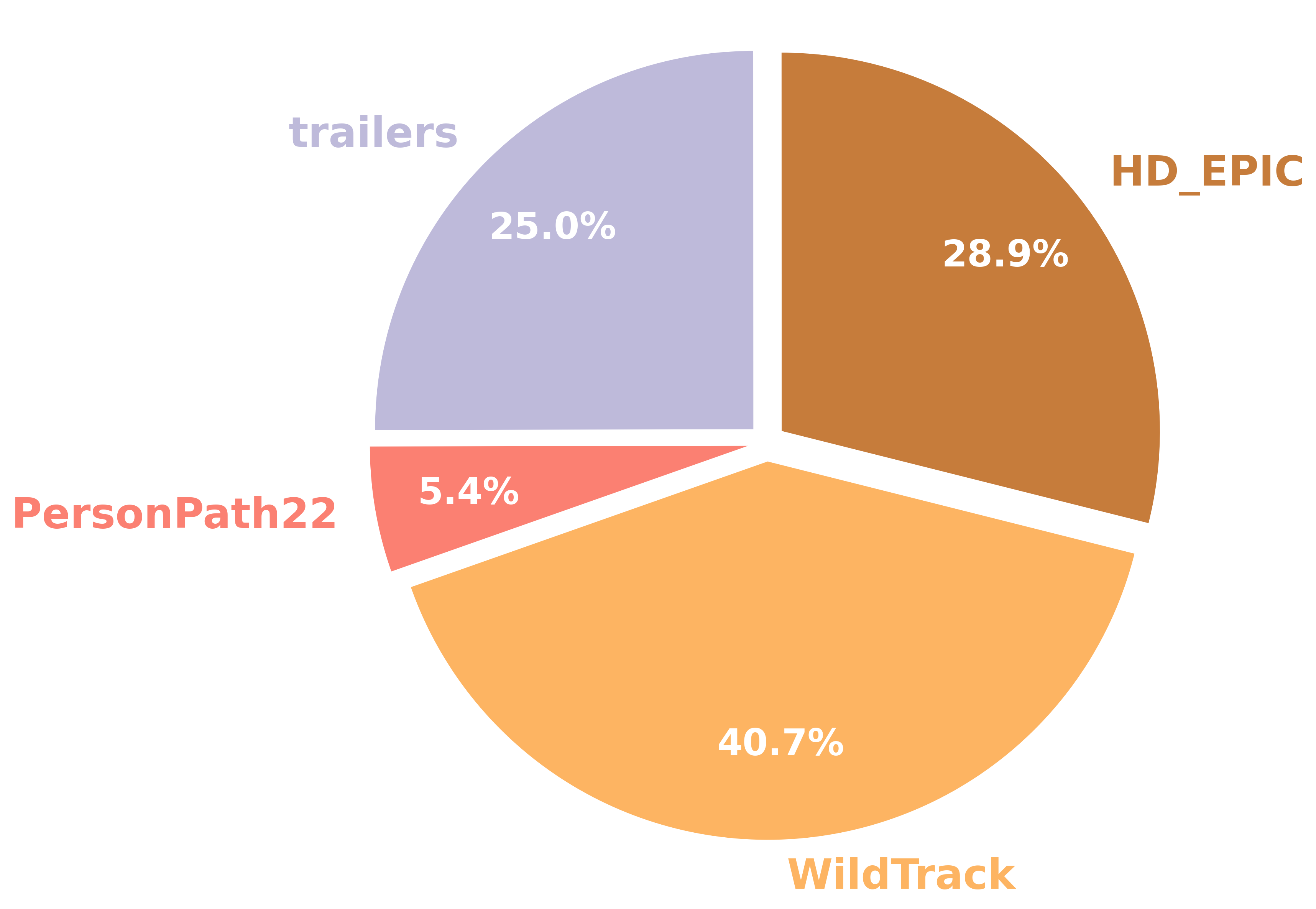
The plots below give a quick snapshot of HERBench: where the questions come from, what they talk about, and how they’re distributed across tasks.
- Source mix — question count by dataset.
- Language — frequent terms in the questions (word cloud).
- Coverage — question count across tasks.


Download and Evaluate
1. Setup
Prerequisites: Python 3.8-3.12, PyTorch 2.0+, and a GPU.
# Clone and install
git clone https://github.com/DanBenAmi/HERBench.git
cd HERBench
# Create env
conda env create -f environment.yml
conda activate herbench
pip install -e .2. Get Data
Download video features and annotation files.
# Via Hugging Face (recommended)
python scripts/download_data.py --source huggingface
# Or via direct download
python scripts/download_data.py --source direct3. Evaluate
Run inference and calculate metrics.
Run Inference
# Qwen2.5-VL (uniform frames)
python evaluation/run_evaluation.py \
model=qwen25vl frame_selector=uniform
# InternVL3.5 (BLIP frames)
python evaluation/run_evaluation.py \
model=internvl35 frame_selector=blipCalculate Metrics
# Accuracy
python evaluation/calculate_accuracy.py \
--predictions results/predictions.json
# MRFS
python evaluation/calculate_mrfs.py \
model=qwen25vl frame_selector=blipCitation
@misc{benami2025herbenchbenchmarkmultievidenceintegration,
title={HERBench: A Benchmark for Multi-Evidence Integration in Video Question Answering},
author={Dan Ben-Ami and Gabriele Serussi and Kobi Cohen and Chaim Baskin},
year={2025},
eprint={2512.14870},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.14870},
}